
Humberto Ortiz Zuazaga
I measured the available bandwidth and round-trip latency for message passing on two publically available message passing libraries running over a homogeneous network of Sun SparcStations over 10 Mbps Ethernet and 155 Mbps ATM networks. The results show conclusively that the ATM network has lower bandwidth than Ethernet for small message sizes, and higher bandwidth for large messages. MPICH has higher bandwidth and lower latency than PVM on both networks. Surprisingly, the peak bandwidth attained during these trials was only 19 Mbps, much smaller than the rated capacity of the ATM network, and smaller than that attained by TCP-over-ATM benchmarks (about 25Mbps). Native PVM and MPICH ATM layer drivers should be developed before any parallel message passing applications are ported to these ATM networks, as the generic TCP layer drivers do not fully exploit the performance advantages of ATM.
PVM (Parallel Virtual Machine [cite PVM]) and MPI (Message Passing Interface [cite MPI]) are two standards for message passing libraries for distributed computing. There are several implementations of PVM and MPI available without charge. Both packages run on a multitude of UNIX workstations and some even on MS-Windows. I tested one publically available implementation of each standard on the University of Texas at San Antonio's coyote lab. The coyote machines are multiprocessor Sparc's connected by both 10 Mbps Ethernet and 155 Mbps ATM networks. I measured the bandwidth and round trip latencies for simple ``ping-pong'' applications running on the same set of machines.
The MPI and PVM benchmarks are very similar in design: one master and
one slave process are started on different machines. The master
performs a loop where it sends a packet to the slave, and awaits the
return packet. The slave does a receive, then retransmits the packet
back to the master. The Solaris 2 high-resolution timer
gethrtime() is used to measure the elapsed time across the loop on
the master.
For the MPICH benchmark, I added a small loop at the start of the program, that sends and receives the test packet 10 times. In MPICH, communication channels are opened dynamically, and this primes the connections between the master and the slave, so that channel establishment costs do not affect the benchmarks. The PVM implementation I tested initializes the communication channels at virtual machine startup time, and so the benchmarks are not affected by this.
<MPI benchmark>=
/* $Id: index.wml,v 1.1.1.1 2003/06/04 16:49:54 humberto Exp $
* Test driver for MPI send and recv routines.
* Humberto Ortiz Zuazaga - 1996/03/17
*/
#include <stdio .h>
#include <stdlib.h>
#include "mpi.h"
#include "../Timer.h"
#define BUFSIZE 1024*10
#define MAX_ITER 1024
int main (int argc, char *argv[]) {
char buffer[BUFSIZE];
int size;
int count;
int my_rank, num_procs;
int source;
int dest;
int tag = 0;
MPI_Status status;
Timer_t start, end, elapsed;
double resolution, seconds, bps, avg_latency;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &my_rank);
MPI_Comm_size(MPI_COMM_WORLD, &num_procs);
if (2 != num_procs) {
fprintf (stderr, "mptest: this program requires exactly two processes.\n");
exit(1);
}
if (0 < argc) {
size = atoi(argv[1]);
} else {
size = BUFSIZE;
}
if ((0 > size) || (BUFSIZE < size)) {
fprintf (stderr, "mpitest: buffer size must be between 0 and %d.\n", BUFSIZE);
exit (1);
}
if (0 != my_rank) {
dest = 0;
/* Get the comm links warmed up */
for (count = 0; count < 10; count++) {
MPI_Send(buffer, size, MPI_CHAR, dest, tag, MPI_COMM_WORLD);
MPI_Recv(buffer, size, MPI_CHAR, dest, tag, MPI_COMM_WORLD, &status);
}
/* MPI_Barrier(MPI_COMM_WORLD); */
start = Timer();
for (count = 0; count < MAX_ITER; count++) {
MPI_Send(buffer, size, MPI_CHAR, dest, tag, MPI_COMM_WORLD);
MPI_Recv(buffer, size, MPI_CHAR, dest, tag, MPI_COMM_WORLD, &status);
}
end = Timer();
elapsed = end - start;
seconds = 1.0 * elapsed / TIMERS_PER_SEC;
bps = (2.0 * 8.0 * size * MAX_ITER) / seconds;
avg_latency = seconds / MAX_ITER;
printf ("Elapsed time = %g sec.\n", seconds);
printf ("Packet size = %d bytes.\n", size);
printf ("Iterations = %d.\n", MAX_ITER);
printf ("Average round trip latency = %g sec.\n", avg_latency);
printf ("Average bandwidth = %g bps.\n", bps);
} else {
dest = 1;
/* Get the comm links warmed up */
for (count = 0; count < 10; count++) {
MPI_Recv(buffer, size, MPI_CHAR, dest, tag, MPI_COMM_WORLD, &status);
MPI_Send(buffer, size, MPI_CHAR, dest, tag, MPI_COMM_WORLD);
}
/* MPI_Barrier(MPI_COMM_WORLD); */
for (count = 0; count < MAX_ITER; count++) {
MPI_Recv(buffer, size, MPI_CHAR, dest, tag, MPI_COMM_WORLD, &status);
MPI_Send(buffer, size, MPI_CHAR, dest, tag, MPI_COMM_WORLD);
}
}
MPI_Finalize();
}
<PVM benchmark>=
/* $Id: index.wml,v 1.1.1.1 2003/06/04 16:49:54 humberto Exp $
* Test PVM comm routines.
*/
#include <stdio.h>
#include "pvm3.h"
#include "../Timer.h"
#ifdef linux
#define FLAGS PvmTaskHost
#define PROGNAME "pvmtest"
#else
#define FLAGS PvmTaskHost | PvmHostCompl
#define PROGNAME "./pvmtest"
#endif
#define BLOCKSIZE 1024*10
#define MAX_ITERS 1024
int main(int argc, char *argv[]) {
int mytid, ptid;
int status, tid;
char buf[BLOCKSIZE];
int i;
Timer_t start, end, elapsed;
double sec;
int size;
char *args[2];
mytid = pvm_mytid();
if (0 > mytid) {
fprintf (stderr, "pvmtest: must be run under PVM.\n");
}
ptid = pvm_parent();
if (PvmNoParent == ptid) {
/* in the master */
if (0 < argc) {
size = atoi(argv[1]);
} else {
size = BLOCKSIZE;
}
if ((0 > size) || (BLOCKSIZE < size)) {
fprintf (stderr, "pvmtest: buffer size must be between 0 and %d bytes.\n", BLOCKSIZE);
exit (1);
}
args[0] = argv[1];
args[1] = 0;
status = pvm_spawn(PROGNAME, (char**)args, FLAGS, ".", 1, &tid);
if (1 == status) {
start = Timer();
for (i = 0; i < MAX_ITERS; i++) {
pvm_initsend(PvmDataDefault);
pvm_pkbyte(buf, size, 1);
pvm_send(tid, 1);
pvm_recv(tid, 1);
pvm_upkbyte(buf, size, 1);
}
end = Timer();
elapsed = end - start;
sec = 1.0 * elapsed / TIMERS_PER_SEC;
printf ("Iterations = %d.\n" , MAX_ITERS);
printf ("Packet size = %d bytes.\n", size);
printf ("Elapsed time = %g seconds.\n", sec);
printf ("Bandwidth = %g bps.\n", (2.0 * 8.0 * MAX_ITERS * size) / sec);
printf ("Avg round-trip latency = %g seconds.\n", sec / MAX_ITERS);
} else {
fprintf(stderr, "pvmtest: can't start slave\n");
exit (1);
}
} else {
/* in child (slave) */
if (0 < argc) {
size = atoi(argv[1]);
} else {
size = BLOCKSIZE;
}
/* printf ("pvmtest (slave): blocksize is %d bytes.\n", size); */
if ((0 > size) || (BLOCKSIZE < size)) {
fprintf (stderr, "pvmtest: buffer size must be between 0 and %d bytes.\n", BLOCKSIZE);
exit (1);
}
for (i = 0; i < MAX_ITERS; i++) {
pvm_recv(ptid, 1);
pvm_upkbyte(buf, size, 1);
pvm_initsend(PvmDataDefault);
pvm_pkbyte(buf, size, 1);
pvm_send(ptid, 1);
}
}
pvm_exit();
exit(0);
}
<Timing routines>=
/* $Id: index.wml,v 1.1.1.1 2003/06/04 16:49:54 humberto Exp $
* High res timer routines.
* Humberto Ortiz Zuazaga - 1996/03/23
*/
#ifndef TIMER_H
#define TIMER_H
#ifdef linux
#include <sys/times.h>
typedef clock_t Timer_t;
struct tms bogus[1];
#define Timer() times(bogus)
#define TIMERS_PER_SEC CLOCKS_PER_SEC
#else
#include <sys/time.h>
typedef hrtime_t Timer_t;
#define Timer gethrtime
#define TIMERS_PER_SEC 1.0e9
#endif
#endif /* TIMER_H */
The performance of both communications libraries was a bit
disappointing. On the coyote network, netperf can get nearly 60 Mbps
(i.e. 60 * 2^20 bits / second, not 6*10^7
bps) over the FORE_STREAM test [cite netperf]. A simple ftp test
on local files (in /tmp) on coyote02 and coyote04 can get nearly
25 Mbps on a 13 MB file.
The bandwidth achieved as a function of message size is summarized in Figure [->]. MPI over the ATM network achieved the highest bandwidth, peaking at about 19 Mbps when the message size was 8192 bytes. MPI over Ethernet is the second highest bandwidth, achieving nearly 8 Mbps of the 10 Mbps rated capacity of Ethernet. As Figure [->] shows, MPI over Ethernet also achieves higher bandwidth than MPI over ATM for message sizes under 1024 bytes in length.
The bottom two curves are PVM over ATM and Ethernet respectively. There was a much smaller difference between these two, and the peak bandwidth was only 6 Mbps.
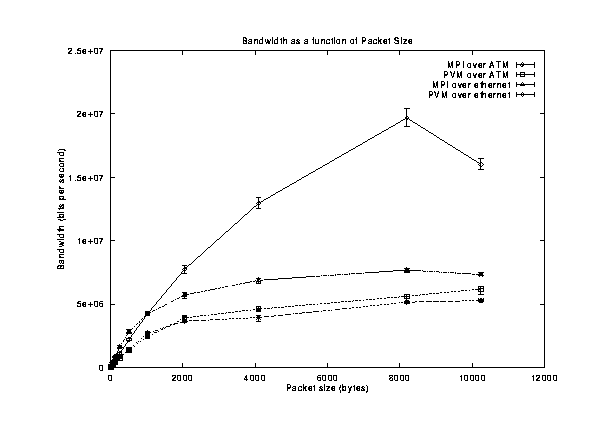
A comparison of bandwidth as a function of transmitted packet size for MPICH and PVM over Ethernet and ATM networks. [*]
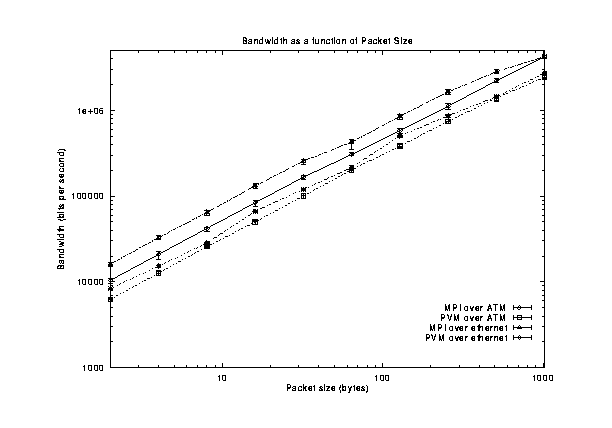
Inset of Figure [<-] showing detail for small message sizes. [*]
The latency results are similar, MPI over ATM having the best performance (lowest round-trip latency) of all, followed by MPI over Ethernet and then PVM. Figure [->] summarizes the results. Again, the inset (Figure [->]) shows that for small messages the latency of MPI over Ethernet is the smallest.
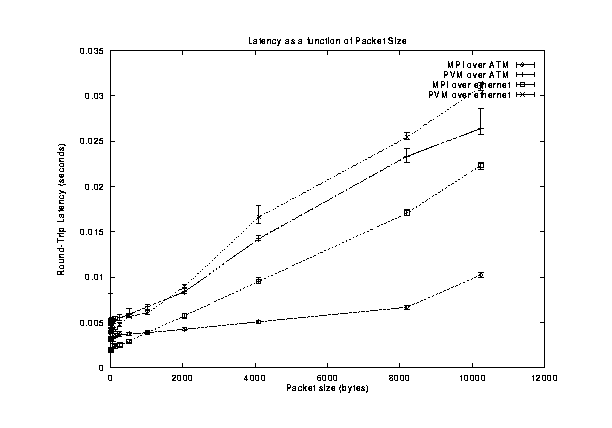
A comparison of round-trip latencies as a function of transmitted packet size for MPICH and PVM over Ethernet and ATM networks. [*]
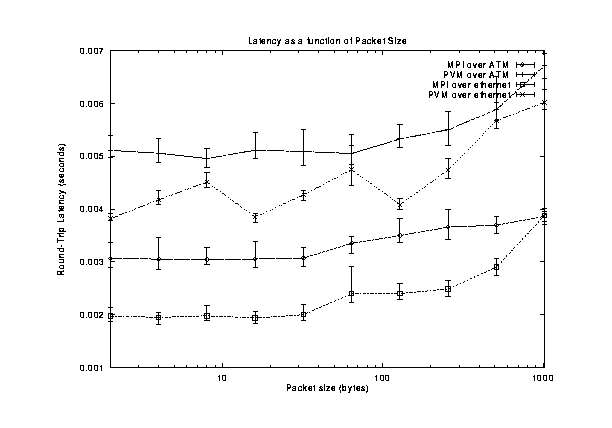
Inset of Figure [<-] showing detail for small message sizes. [*]
The performance results for PVM and MPI over the ATM network are quite disappointing. For the vast majority of distributed programs (which use small messages), both the bandwidth and the latency would be better if the programs ran on 10 Mbps Ethernet. Even with extremely large message sizes (8 KB) the bandwidth is less than 13% of the rated capacity of the ATM network. It is likely that 100 Mbps Ethernet, and especially dynamically link balanced multiple Ethernet card setups like those used in project Beowulf could obtain significantly higher throughput than the ATM.
Since the performance of raw FTP over the ATM network is not much higer than MPI and MPI over Ethernet does get close to the rated capacity, it it likely that the limiting factor is Fore's TCP over ATM implementation. If so, a port of MPICH's channel software to Fore's API or U-Net could also see significantly better performance. In fact, the U-Net project claims it obtains much better performance than even Fore's API, and also noted that Fore's TCP over ATM was indeed slow.
MPICH's internal structure is currently undergoing revision. A port to use a faster ATM interface should either use LAM 6.0, or wait for version 1.0.13 of MPICH, which should have the new internal architecture in place.
*[2] Netperf. Available on the Internet from <URL:http://www.cup.hp.com/netperf/NetperfPage.html>
[3] MPICH. Available on the Internet from <URL:http://www-unix.mcs.anl.gov/mpi/>
Most recent change: 2007/9/3 at 22:14
Generated with GTML